HTML Parse Tree Search
Tree is an abstract data type in computer science. Now that you are a programmer, Binary Tree and AVL Tree must feel like primary school math (haha, I am joking, tree is my worst nightmare when it comes to interview). For a webpage, if you right click and select view source (CTRL+U in both IE & Chrome), you will end up with a bunch of codes like this.

The codes are written in HTML. The whole HTML script is a tree structure as well. The HTML parse tree looks like this.
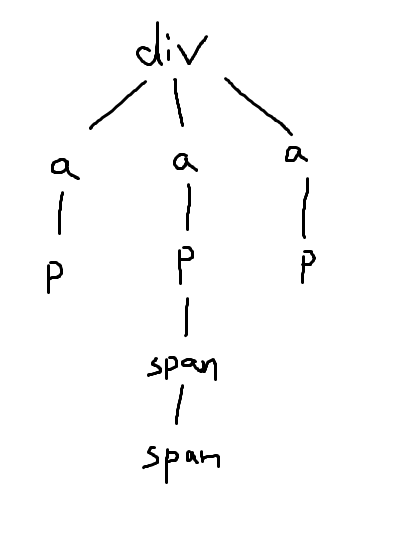
There is something interesting about HTML parse tree. The first word after the left bracket is HTML tag (in tree structure we call it node). In most cases, tags come in pairs. Of course, there are some exceptions such as line break tag <br> or doc type tag <!DOCTYPE>. Usually the opening tag is just tag name but the closing tag has a slash before the name. Different tag names represent different functionalities. In most cases, there are only a few tags that contain information we need, e.g., tag <div> usually defines a table, tag <a> creates a hyperlink (the link is at attribute href and it may skip prefix if the prefix is the same as current URL), tag <img> comes up with a pic (the link is hidden in attribute src), tag <p> or <h1>-<h6> normally contains text. For more details of tagging, please refer to w3schools.
It is vital to understand the basics of HTML parse tree because most websites with simple layout can easily be traversed via a library called BeautifulSoup. When we use urllib or other packages to request a specific website via python, we end up with HTML parse tree in bytes. When the bytes are parsed to BeautifulSoup, it makes life easier. It allows us to search the tag name and other attributes to get the content we need. The link to the documentation of BeautifulSoup is here.
For instance, we would love to get the link to the quiz on Dragon Ball, we can do
result.find('div',class_='article article__list old__article-square').find('a').get('href')
or
result.find('div',attrs={'class':'article article__list old__article-square'}).find('a').get('href')
Here, result is a BeautifulSoup object. The attribute find returns the first matched tag. The attribute get enables us to seek for attributes inside a tag.
If we are interested in all the titles of the articles, we do
temp=result.find('div',class_='article article__list old__article-square').find_all('a')
output=[i.text for i in temp]
or
temp=result.find('div',attrs={'class':'article article__list old__article-square'}).find_all('a')
output=[i.text for i in temp]
The attribute find_all returns all the matched results. .text attribute automatically gets all str values inside the current tag. The second article has a subtitle 'subscriber only'. So we will have a rather longer title for the second article compared to the rest.
You can refer to CME1 for more details. Please note that CME1 is an outdated script for Chicago Mercantile Exchange. Due to the change of the website, you cannot go through HTML parse tree to extract data any more. Yet, the concept of HTML parse tree is still applicable to other cases.
Click the icon below to be redirected to GitHub Repository