JSON
JSON, is the initial for JavaScript Object Notation. Like csv, it is another format to store data. According to the official website of JSON, it is easy for humans to read and write. Pfff, are you fxxking with me? Anyway, an SVG image generated by D3.js is normally associated with JSON data. Finding JSON makes it possible to extract data of an interactive chart. If you open JSON with notepad, you will see something like this.

Gosh, the structure is messy and I will have a panic attack very soon. Duh! Just kidding. If you are familiar with adjacency list in graph theory, you will find it very easy to understand JSON. If not, do not worry, JSON is merely dictionaries inside dictionaries (with some lists as well). To navigate through the data structure, all you need to know is the key of the value.
Reading a JSON file in Python is straight forward. There are two ways.
There is a default package just called json, you can do
import json
with open('data.json') as f:
data = json.load(f)
print(data)
Nevertheless, I propose a much easier way. We can parse the content to pandas and treat it like a dataframe. You can do
import pandas as pd
df=pd.read_json('data.json')
print(df)
Reading JSON is not really the main purpose of this chapter. What really made me rewrite the scraper for CME is the change of website structure. In April 2018, I could not extract data from searching for HTML tags any more. I came to realize that CME created a dynamic website by JavaScript. The great era of BeautifulSoup was water under the bridge. At this critical point of either adapt or die, I had to find out where the data came from and develop a new script. Guess where?
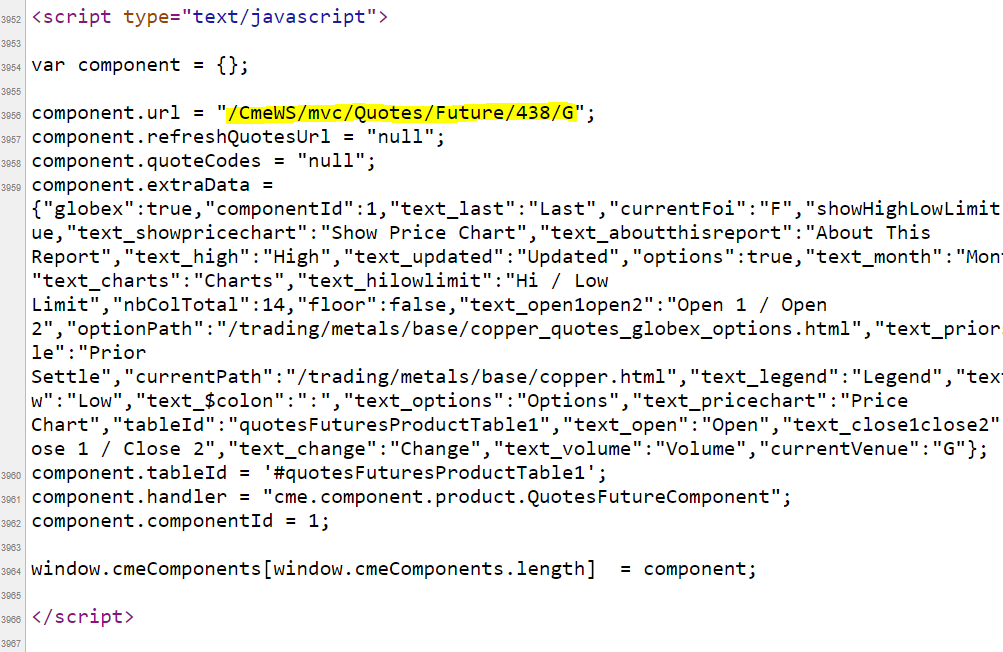
The URL is still in page source! The HTML tag for the hidden link is <script>. As I have mentioned at the beginning of this README file, scraping is about patience and attention to details. If you try to search all <script> tags, you will end up with more than 100 results. It took me a while for me to sniff the data source. My friends, patience is a virtue.
As for other websites, we may not be that lucky. Take Euronext for example, you won't find any data in page source. We have to right click and select inspect element (CTRL+SHIFT+I in Chrome, F12 in IE).
The next step is to select Network Monitor in a pop-up window. Now let's view data.
There is a lot of traffic. Each one contains some information. Currently what truly matters to us is the request URL. Other information such as header or post form data will be featured in a later chapter. We must go through all the traffic to find out which URL leads to a JSON file. Once we hit the jackpot, we right click the request and copy link address.
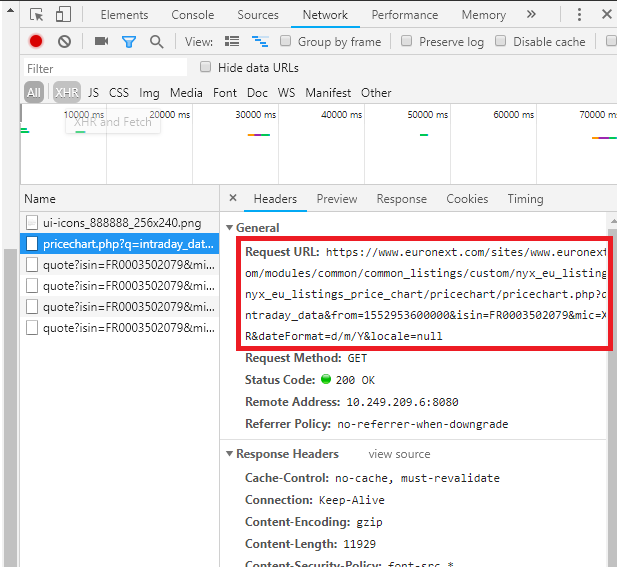
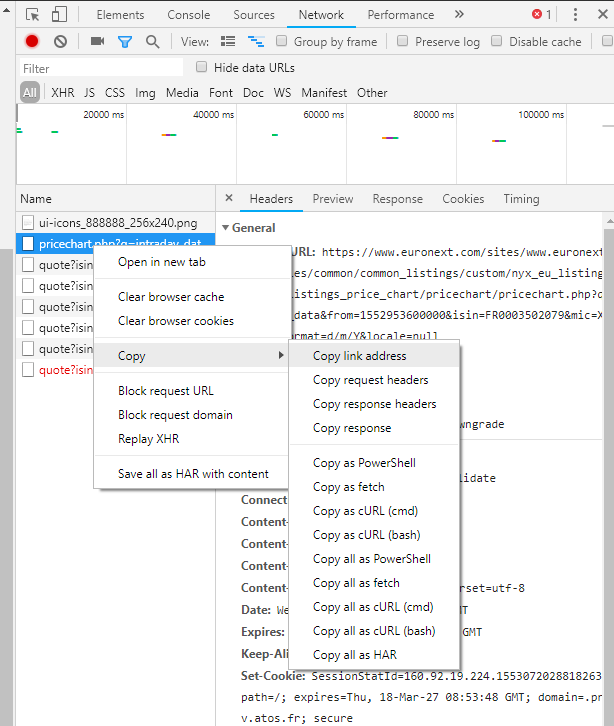
Voila!
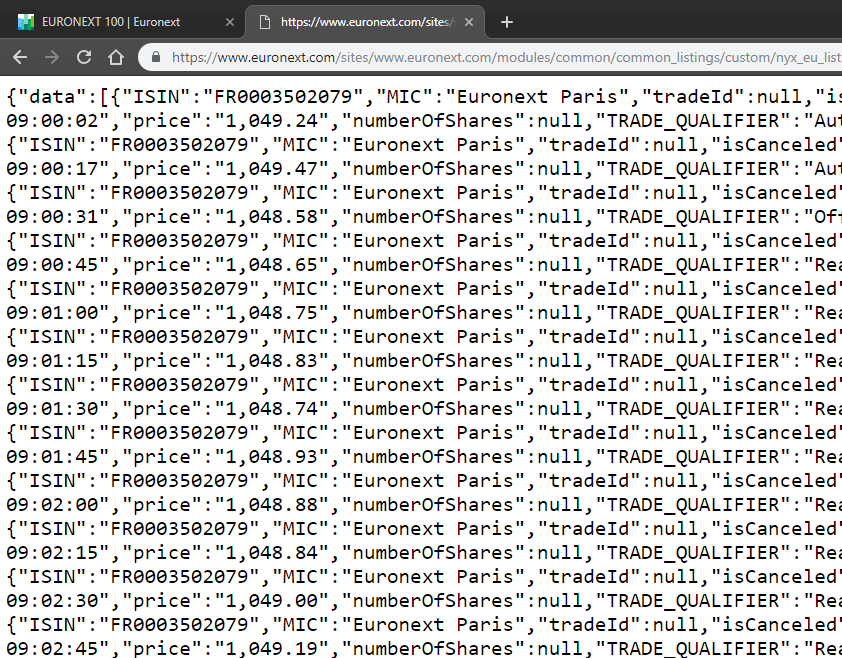
Euronext is still considered an easy one. Sometimes you have to post a form with valid header to get the JSON file. You will see that in the first chapter of advanced level. For more details of JSON, feel free to take a look at CME2. Please note that CME2 has replaced CME1 to be the available scraper for Chicago Mercantile Exchange. There is also CME3 which specializes in option data.
Click the icon below to be redirected to GitHub Repository