Legality
The purpose of web scraping is to extract online data in a large scale by automation. Nevertheless, some of the website content may be under copyright protection called Digital Millennium Copyright Act (even pornography is protected by DMCA). This adds a little complication to our projects. Even open source data is subjected to fair use, yet the interpretation of fair use is always trivial. There have been many lawsuits around web scraping. Sometimes the scrapers lose sometimes the scrapers win. The actual verdict varies case by case. Law is equal to anyone. Except those with deep pockets are more equal than the others. Nobody really wants to be that sucker who pays the fine. I am not licensed to offer any practical legal counselling but I do have a couple of useful hints for you.
Disclaimer
In most cases, you can find terms of web scraping in the declaration of the content rights or other similar legal sections. These terms are long, sophisticated and incomprehensible (insert the joke here, can you speak English 😁 ). The most straightforward way is to add /robots.txt behind any website domain. You will find out the policy set by the website administrator. Usually it tells you what the restrictions are.
For instance
https://www.lemonde.fr/robots.txt
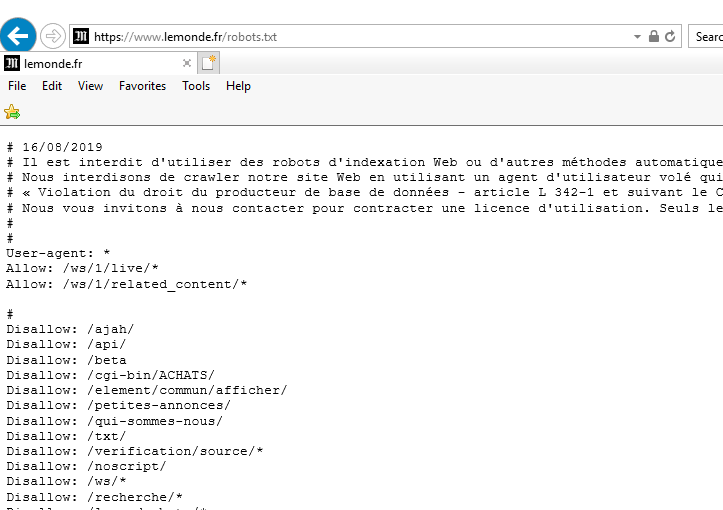
In English, all user agents (* refers to all) are allowed for the following 2 sub directories.
/ws/1/live/*
/ws/1/related_content/*
But forbidden for the following directories
/ajah/
/api/
/beta
/cgi-bin/ACHATS/
/element/commun/afficher/
/petites-annonces/
/qui-sommes-nous/
/txt/
/verification/source/*
/noscript/
/ws/*
/recherche/*
Traffic
An ethical way to do web scraping is to pause your request from time to time. Using distributed web scrapers, the algorithms send requests much faster than clicking website in a web browser. Some of the small websites could encounter server overload and service shutdown. If you are being too aggressive, you might trigger an anti-abuse system. Usually it results in IP address blocking, perhaps temporary for a few hours or days, unlikely to be permanent. In worst cases, your scraping could be identified as DDoS attack. State sponsored hacking groups normally launch these sorts of attacks. These attacks are serious offense under Computer Fraud and Abuse Act. You could be convicted in criminal cases and end up in jail. Hence, there is no harm in waiting for a few extra seconds to disguise as a human viewer.
In Python, we just do
import time
import random as rd
time.sleep(rd.randint(1,5))
Privacy
Thanks to European Union, now we have General Data Protection Regulation. Apart from GDPR, California is about to roll out California Consumer Privacy Act. This brings challenges to the thriving business of data broker. Ideally most of us build web scrapers to scrape open data source. If you are scraping résumé from LinkedIn or stalking someone on social media, and the person is fallen under the jurisdiction of European Court of Justice, then it will be tricky. Is it considered obtaining and processing personal data without someone's consent? I can't tell. As a consumer, I fully support the regulation safeguarding my personal data. As a coder, I would've recused myself from building a web scrapper with potential violations.
API
Last but not least, if there is API which implies it is legitimate, always use API instead of building your own toolbox. Why reinvent the wheels and bear the risks?
Click the icon below to be redirected to GitHub Repository