Sign-in
Congrats! I assume you have mastered entry-level web scraping. Since we come to more advanced level, we will have to deal with more complex issues. In this chapter, we will talk about how to sign into a website in Python. Please bear in mind that we will only discuss login without any captcha or other Turing Test (google's reCAPTCHA is one of the worst). It doesn't mean captcha is the dead end for scraping. There are two ways to bypass captcha, manually downloading image for human recognition or using external package to do image recognition. You will find something here.
Well, login is no magic. Traditionally it is posting a form consists of critical information to a certain address. When each piece of information matches the record in website backend database, the website will assign a token to you. Token is like security clearance. It enables you to visit the content that requires login. Always remember to insert a token into the header when you got one after authentication.
Big companies like Facebook or Twitter use a slightly different approach called CSRF token. The website sends a token to you before sign-in. It goes without saying that CSRF token must be presented at login. There will be no more token assigned to you after authentication because the cookies will take care of everything. Think of CSRF as buying TTP in Madrid, once you tap it on the card reader to pass the gate, you do not need it to visit any station or exit the metro system.
Let's look at a simple case, a website called CQF. This great website features many free reports and videos on quantitative finance. But, there is always a but, the annoying part is resources are exclusive to registered users. Thus, we will be forced to include the login part in our python scraper. As usual, we always take a quick look at the website before coding. When we log in, we need to inspect element to seek for the login activity (if you forget how to do this, please refer to chapter 2 in the beginner level). There are quite a few activities when we log in, right? The quickest way to distinguish the login from the rest is to search your username and password. Because username and password are normally unhashed.
Now that we have located the login activity, there are three key things we need to keep an eye on. The first one is Request URL. It will be the URL we post our form to. Pay attention to Request Method. The login is often POST method, rather than GET method.
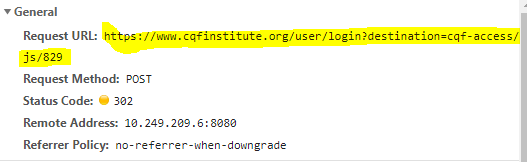
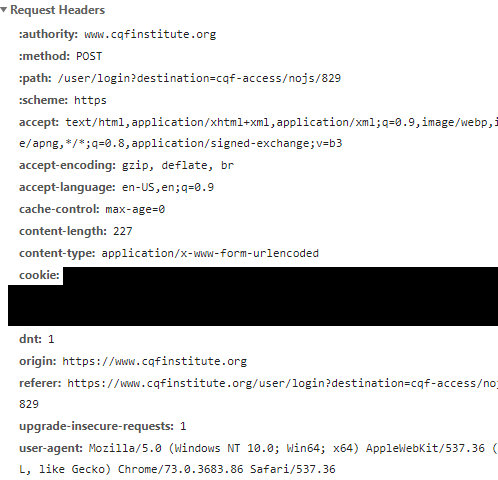
The second one will be Request Headers. Headers are great tools to disguise your scraping as an internet browser. They are called headers because you would spend most of your time scratching your head to get them right. We can observe tons of information in the headers. Only a small bit of them are genuinely useful to the login. An effective way is to exclude cookies and anything contains hashed information. Nonetheless, this is not always the case. Some websites filter out machines by valid cookies with hashed information for login. If you accidentally exclude those headers, you may trigger the alarm of the website and end up with some form of captcha.
My apologies for the redaction in these headers. The redaction plays a vital role here to protect my privacy. It turns my headers into some confidential documents from MI6.
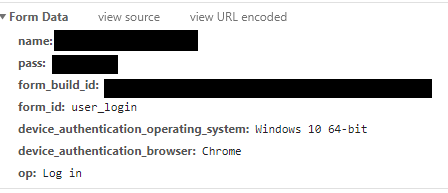
The last but not least one will be Form Data. It contains the critical information for authentication, such as username and password.
There is another part called Query String Parameters. We do not encounter it very often at login. It is more frequently seen in data query though.

Once we have gathered everything we need, we can simply do
session.post(url,headers={'iamnotarobot':True},
data={'username':'lanarhodes4avn',
'password':'i<3ellahughes'},
params={'id':'jia.lissa'})
The session will automatically update its cookie after posting a form. Generally speaking, the website gives a token in return (CQF does not). And the response is likely to be in JSON format, then we do
session.headers.update({'token':response.json()['token']})
We have obtained the security clearance now. We can snoop around every corner as we please. Quite simple, isn't it? For more details, feel free to click CQF. If you crave for a bigger challenge, why don't you start with scraping a private instagram account?
Click the icon below to be redirected to GitHub Repository